Video Transformers
What are Video Transformers?
Video Transformer is a recently developed deep learning model for processing and analyzing video data. It is based on the Transformer architecture.
In the context of video understanding, transformers excel at capturing long-range dependencies and relationships within video sequences. They can effectively encode and understand the temporal and spatial information present in videos.
To achieve this, video transformers typically employ an encoder-decoder architecture. The encoder processes the input video frames, extracting meaningful features and representations. The decoder then uses these encoded features to generate predictions or outputs based on the learned information.
One of the key components of video transformers is the self-attention mechanism. Self-attention allows the model to attend to different parts of the video frames, giving more weight to relevant regions or frames. This attention mechanism helps the model capture important temporal and spatial relationships, enabling it to understand the context and dynamics of the video. Video Transformer models can be used for a variety of video processing tasks, including: Video classification, video captioning, and video generation.
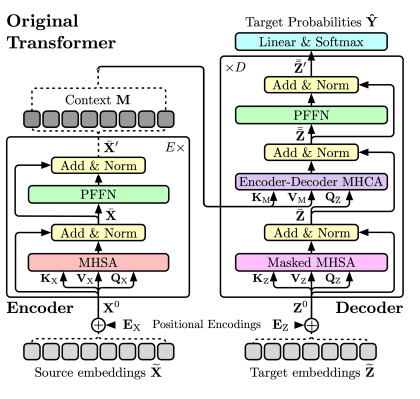
Transformer model architecture
1. Encoder: The encoder takes in the input video frames and processes them to capture their temporal and spatial information. It consists of multiple layers of self-attention and feed-forward neural networks. Each layer in the encoder independently attends to different parts of the video frames and aggregates information from the entire sequence. This allows the model to capture long-range dependencies and relationships within the video.
2. Decoder: The decoder takes the encoded information from the encoder and generates predictions or outputs based on it. It also consists of multiple layers of self-attention and feed-forward neural networks. The decoder attends to the encoded video frames and generates predictions step by step, often autoregressively. The predictions can be in the form of video classification labels, object detections, or even generated video frames.
3. Self-Attention Mechanism: The self-attention mechanism is a key component of the transformer model. It allows the model to attend to different parts of the video frames and capture relevant information for analysis. Self-attention computes attention weights for each element in the input sequence, enabling the model to focus on important features and relationships.
4. Positional Encoding: Since transformer models do not inherently capture the sequential order of the input, positional encoding is used to provide the model with information about the relative positions of the video frames. This helps the model understand the temporal dynamics of the video.
Overall, the transformer model for videos leverages the power of self-attention and positional encoding to effectively process and analyze video data, capturing both spatial and temporal information. This architecture has shown great success in various video understanding tasks.
Video Transformer model
The Video Transformer model has of two major parts: the spatial transformer and the temporal transformer. The spatial transformer is in charge of processing the spatial information of each video frame, whereas the temporal transformer is in charge of processing the temporal information between frames. These two components work in tandem to provide a thorough knowledge of the video data.
A convolutional neural network (CNN) is employed in the spatial transformer to extract features from each frame. The extracted features are subsequently put into the transformer architecture’s self-attention mechanism. The self-attention method is utilized to prioritize each feature and generate a more representative feature vector for each frame.
The temporal transformer is similar to the spatial transformer, but that it considers frame relationships. The temporal transformer employs the same self-attention mechanism as the spatial transformer, but it also employs a temporal attention mechanism to assess the significance of each frame in the movie. This enables the model to focus on the most significant frames in the video while ignoring irrelevant or redundant frames.
The Video Transformer model may be trained using massive datasets of videos and labels. The model learns to recognize patterns and correlations in video data and make predictions based on this information during the training process. The trained model can then be used to make predictions new, previously unseen video data.
Step by step process of Video Transformers
The Video Transformer process breaks down into high-level steps as follows:
- Splitting the video into frames: The first step is to split the video into individual frames. This enables the model to process and extract characteristics from each frame separately.
- Resizing and normalization of frames: After the frames have been extracted, they are usually resized to a similar resolution and normalized to have a zero mean and unit variance. This is done to prevent the model from favoring larger or brighter frames.
- Splitting each frame into patches: Each frame is divided into patches: The following step is to divide each frame into smaller portions. This enables the model to capture fine-grained video data features and increase its accuracy.
- Adding positional encoding: Positional encoding is applied to each patch to ensure that the model is aware of the relative position of each patch in the frame. The positional encoding encodes each patch’s relative position as a set of vectors appended to the patch’s feature vector.
- Feeding the patches into the spatial transformer: The patches are then input into the spatial transformer, which extracts features from each patch with the use of a CNN and a self-attention mechanism.
- Concatenating the frames: Each frame’s features are concatenated and sent into the temporal transformer. The temporal transformer uses a self-attention mechanism and a temporal attention mechanism to process the temporal correlations between frames.
And after steps above a classification head is added to the model, which makes predictions based on the processed video input. A linear layer and a softmax activation function, which outputs a probability distribution across the possible classes, are commonly included in the classification head.
Advantages
1. Capturing long-range dependencies: Video transformers excel at capturing long-range dependencies and relationships within video sequences. They can effectively model temporal and spatial information, allowing for a more comprehensive understanding of videos.
2. Flexible architecture: Transformer models offer a flexible architecture that can be adapted to various video analysis tasks. They can be easily modified and fine-tuned for specific applications, making them versatile for different use cases.
3. Parallel processing: Video transformers can process video frames in parallel, which enables efficient computation and faster inference times compared to sequential models. This parallel processing capability is particularly beneficial for real-time video analysis.
4. Contextual understanding: Transformers can capture contextual information by attending to different parts of the video frames. This enables a more nuanced understanding of the video content, leading to improved performance in tasks such as object recognition, action recognition, and video generation.
Disadvantages
1. Computational complexity: Transformers are computationally intensive models, requiring significant computational resources and memory. Training and inference with video transformers can be time-consuming and resource-intensive, especially for large-scale video datasets.
2. Large memory footprint: Video transformers often have a large memory footprint due to the self-attention mechanism, which requires storing attention weights for each frame. This can limit their scalability and deployment on resource-constrained devices.
3. Lack of interpretability: Transformers are known for their black-box nature, making it challenging to interpret the internal workings and decision-making process of the model. This lack of interpretability can be a drawback in certain applications where explainability is crucial.
4. Data requirements: Video transformers typically require large amounts of labeled training data to achieve optimal performance. Acquiring and annotating such datasets can be time-consuming and expensive, especially for specialized video analysis tasks.
Endnote
Video transformers have emerged as a powerful tool in the field of computer vision, enabling the analysis and understanding of video data.
As research in this area continues to evolve, video transformers hold great potential for further enhancing video analysis and understanding.